
O Synapse divide seus recursos em “famílias”, a qual cada uma dessas famílias é composta por “blocos” que consistem na unidade básica para o funcionamento do programa. Na figura seguinte é demonstrado as famílias e os blocos, ambas contidas no tópico “Modelagem”.
Antes de descrever o funcionamento dos principais blocos do programa, é importante entender o fluxo de trabalho do software. O Synapse, em resumo, necessita da definição de 4 parâmetros básicos para a solução de um problema. A priori o tutorial será focado em problema de otimização para facilitar a explicação.
O primeiro deles consiste na definição das soluções inicias do problema que pode ser encontrado na família “DOE” (Design of Experiments). A seguir é necessário definir o processo que será realizado (otimização, análise ou interpolação) na família “Modelo”, bem como a escolha do algoritmo de otimização adequado as necessidades do problema na família “Otimizador”. Por fim, é necessário inserir a disciplina presente na família “Modelo”, que representa o problema a ser resolvido. A figura a seguir demonstra como fica esse fluxograma no software.

Após a definição desses quatro parâmetros que será chamado de Conjunto 1, é necessário desenvolver a disciplina, ou seja, modelar o problema que deve ser resolvido de fato. Para isso o programa oferece diversos blocos que possibilita essa modelagem, os quais interagem entre si através de setas, permitindo ao usuário uma visualização clara dos dados de entrada e saída de um bloco. Por exemplo, na Figura 2 o algoritmo de otimização receber como dado de entrada as soluções inicias (DOE) e tem como saída os dados necessários para que o processo de otimização ocorra.
A tabela a seguir contempla os principais blocos utilizados no Synapse.
![]()
Consiste na definição das variáveis do projeto, geralmente aquilo que se busca otimizar. Não necessita de dados de entrada, apenas saída. É necessário definir os limites de variação.
![]()
Consiste em um bloco que armazenará um dado de saída, geralmente após alguma operação. Necessita de dados de entrada e saída.
![]()
Consiste na definição das restrições do problema (quando existe), geralmente aplicada a um atributo. Necessita apenas de dados de entrada.
![]()
Consiste na definição do objetivo do problema modelado, no caso da otimização, se é desejado a minimização ou maximização de uma variável. É geralmente aplicada a um atributo. Necessita apenas de dados de entrada.
![]()
Consiste na definição de parâmetros fixos e inalterados do problema, como constantes naturais, por exemplo (gravidade, densidade do material etc.). Não necessita de dados de entrada, apenas saída.
![]()
Consiste no bloco que irá operacionalizar outros blocos através de equacionamentos matemáticos. Necessita de dados de entrada (variáveis e/ou parâmetros) e fornece dados de saída (geralmente atributos).
Vale destacar que estes são os blocos principais visando o primeiro contato do usuário ao software e relacionados a solução de problemas simples da engenharia. À medida que a complexidade dos problemas cresce, se impossibilita restringir a modelagem apenas com esses blocos.
Estes blocos descritos anteriormente, são organizados de modo a representar o problema a ser solucionado, ou seja, eles descrevem a disciplina do software. Será dado o nome de Conjunto 2 para a definição de disciplina. Portanto, para que o software funcione corretamente é necessário existir ambos os conjuntos na modelagem, pois apesar de não estarem conectados visualmente, eles se relacionam para gerar a resposta ao usuário.
Após a modelagem dos conjuntos 1 e 2, o usuário deve atentar-se a janela de avisos para garantir não haver nenhum problema na modelagem. Se não há mensagens de aviso significa que o modelo está completo. Por fim, basta rodar a otimização na guia “Executar → Executar Otimização”. A figura abaixo ilustra os últimos procedimentos descritos.
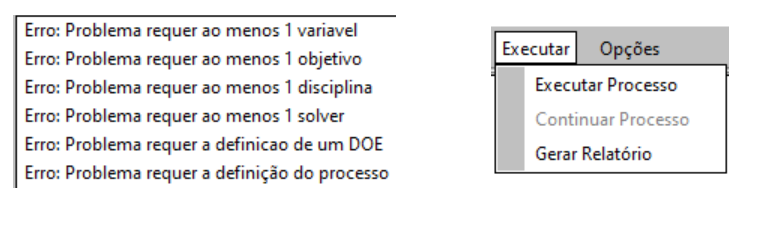
À esquerda a janela de avisos do software e à direita o comando para executar o programa.